






The Lance-Williams algorithm spark is an effective progressive clustering strategy broadly utilized in information investigation and machine learning. Especially suited for huge datasets, it is outlined to perform productively on conveyed computing stages like Apache Start. This article investigates the Lance-Williams calculation, its usage in Start, and its different applications while highlighting its qualities and limitations.
Try to Understand the Lance-Williams Algorithm
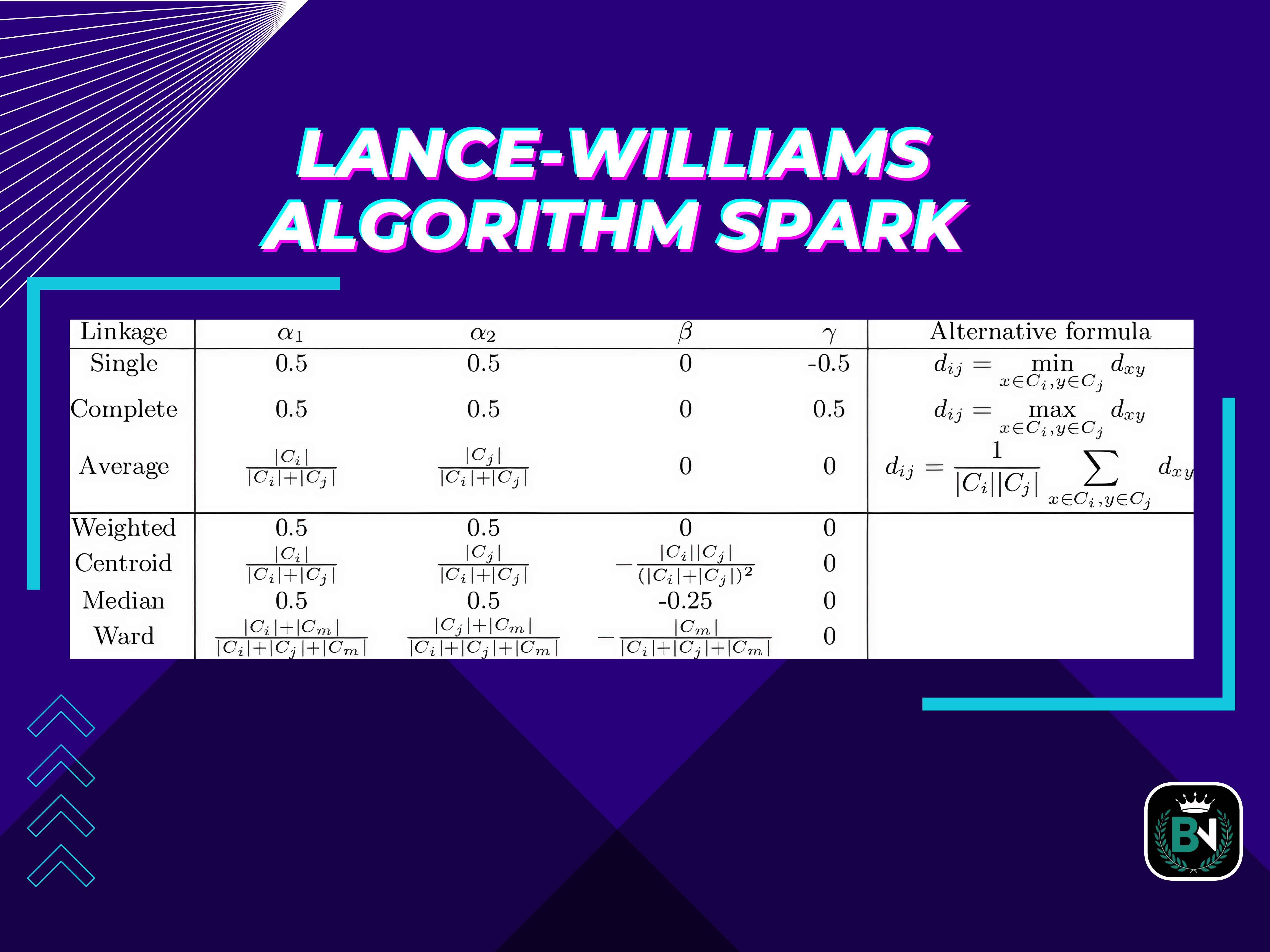
The Lance-Williams algorithm spark is an agglomeration various-leveled clustering strategy. This implies it begins with personal information focuses and steadily blends them into bigger clusters until as it were one cluster remains.
The algorithm decides how comparative two information focuses or clusters are utilizing a remove metric. At each step, it combines the most comparative information to focuses or clusters based on the Lance-Williams disparity coefficient.
The Lance-Williams Dissimilarity Coefficient
The dissimilarity coefficient is defined as follows:
d(A,B)=2⋅d(A,C)⋅d(B,C)d(A,C)+d(B,C)d(A, B) = \frac{2 \cdot d(A, C) \cdot d(B, C)}{d(A, C) + d(B, C)}d(A,B)=d(A,C)+d(B,C)2⋅d(A,C)⋅d(B,C)
In this formula:
- A and B are the clusters being merged.
- C is a third cluster that is not being merged.
- d(A,B)d(A, B)d(A,B), d(A,C)d(A, C)d(A,C), and d(B,C)d(B, C)d(B,C) represent the distances between the clusters.
A lower value of d(A,B)d(A, B)d(A,B) indicates that the clusters A and B are more similar, while a higher value suggests they are less similar.
Implementing the Lance-Williams Algorithm Spark
To execute the Lance-Williams algorithm spark, you can utilize the MLlib library, which offers an assortment of machine-learning calculations, and counting clustering strategies. Underneath is a basic case of how to utilize the Lance-Williams algorithm spark.
Sample Code
Here’s how you can implement the Lance-Williams algorithm using Scala:
import org.apache.spark.mllib.clustering.LanceWilliamsHAC
import org.apache.spark.mllib.linalg.Vectors
// Create a DataFrame with the data to be clustered
val data = spark.createDataFrame(Seq(
(Vectors.dense(1.0, 2.0)),
(Vectors.dense(3.0, 4.0)),
(Vectors.dense(5.0, 6.0))
)).toDF(“features”)
// Create a Lance-Williams HAC model
val model = new LanceWilliamsHAC()
.setDistanceMeasure(“euclidean”)
// Train the model
val clusters = model.run(data)
// Print the clusters
clusters.foreach(println)
In this code, we begin with making an information outline with three information focuses, each containing two highlights. At that point, we initialize a Lance-Williams Progressive Agglomeration Clustering (HAC) to demonstrate and indicate the Euclidean separate metric. After preparing the show on the information, we print the coming about clusters.
Applications of the Lance-Williams Algorithm
The Lance-Williams algorithm finds utility in various fields, demonstrating its versatility. Some key applications include:
1. Customer Segmentation
Businesses can utilize the Lance-Williams algorithm to bunch clients based on statistical, behavioral, and value-based information. By distinguishing distinctive client fragments, companies can tailor their showcasing methodologies to meet the special needs of each gather, eventually upgrading client fulfillment and loyalty.
2. Document Clustering
Researchers can cluster archives based on their substance to organize and recover data more viably. The Lance-Williams algorithm makes a difference in distinguishing bunches of related records, streamlining the inquiry about preparing and moving forward data access.
3. Image Segmentation
In computer vision, clustering pixels in a picture based on their color and surface permits for the recognizable proof of objects and locales of intrigue. The Lance-Williams algorithm can essentially upgrade protest acknowledgment and picture division errands, driving way better results in different applications.
4. Bioinformatics
The algorithm can also be connected in bioinformatics to cluster qualities or proteins. It is based on their arrangement or expression of information. This clustering makes a difference when researchers recognize connections and capacities among qualities and proteins, helping in understanding complex organic frameworks.
Why the Lance-Williams Algorithm Matters?
The Lance-Williams algorithm is basic for information examination and machine learning assignments due to its productivity and adaptability. Here are a few of the benefits of utilizing this algorithm:
Efficiency
The Lance-Williams algorithm is known for its speed and effectiveness. This makes it one of the best choices for various leveled clustering, particularly with expansive datasets.
Scalability
Implementing the algorithm in Apache Start permits it to scale successfully, dealing with gigantic datasets consistently. This versatility is vital in today’s data-driven world.
Versatility
The wide run of applications, from client division to bioinformatics, demonstrates the algorithm’s flexibility, making it an important instrument in different spaces.
Getting the Most Out of the Lance-Williams Algorithm
To maximize the benefits of the Lance-Williams algorithm, understanding its qualities and impediments is crucial.
Strengths
- Efficiency: It is one of the speediest progressive clustering algorithms available.
- Scalability: Works well with huge datasets due to its integration with Apache Spark.
- Versatility: Appropriate to different issues, making it appropriate for distinctive fields.
Limitations
- Sensitivity to Noise: Clamor and exceptions in the data can influence the calculation, leading to inaccurate clustering results. Managing these issues is essential for achieving reliable clustering outcomes.
- Interpretability: As the dataset measures increments, translating the clustering comes about can end up challenging.
Mitigating Limitations
To address these impediments, consider the taking-after strategies:
- Preprocessing: Clean the information to evacuate clamor and exceptions, sometimes recently clustering.
- Visualization: Utilize visualization strategies to analyze clustering comes about and recognize potential issues.
- Comparison: Apply numerous clustering calculations to approve comes about and decide the most vigorous solution.
Wrapping Up
The Lance-Williams algorithm Spark is a vigorous instrument for various leveled clustering, advertising proficiency, and versatility for expansive datasets. Its applications span different spaces, making it a flexible choice for information investigation and machine learning assignments.
By understanding its qualities and restrictions, you can successfully use the Lance-Williams algorithm in your ventures, guaranteeing you get significant experiences from your information. If you are looking for a capable clustering strategy, consider utilizing the Lance-Williams algorithm in Apache Spark for your information examination needs.





